
ContentNext: Scaling content design with AI
Overview
ContentNext is an AI-powered content design system created for Fusion teams at Autodesk. It helps designers and engineers produce consistent, Weave-compliant in-product copy such as tooltips, warnings, errors, success messages, and notifications. The key shift was moving from a bespoke app to a Custom GPT plus Cursor workflow so teams could work where they already are.
Key facts
- Project duration: 6 months (October 2025 to present)
- Role: Sole designer, owning prompt architecture, testing, and production decision
- Cross-functional inputs from CXD reviewers, leadership, and content design leads
Challenges
- No dedicated user research resource for formal studies
- Need to move quickly in a fast-changing product environment
- Balancing governance depth with speed-to-value
Approach
- Improved readability metric language to remove ambiguity around target scores
- Encoded Weave standards into a modular prompt architecture
- Tested multiple delivery models before selecting production route
- Ran controlled guided-vs-free-text comparisons
Problem
Content design was becoming a delivery bottleneck. Engineers needed compliant copy late in build cycles, and guidance was fragmented across docs, Confluence, and tribal knowledge. Informal AI drafting was fast but inconsistent, with uneven structure and tone.
User pain points
- Engineers needed quality UI copy without content design expertise
- Content designers spent time rewriting drafts instead of shaping systems
- Ad-hoc AI outputs lacked consistency and Weave compliance
Business challenges
- Inconsistent copy quality across Fusion surfaces
- Manual reviews consumed CXD team capacity
- No scalable way to enforce standards at point of creation
- Low confidence in whether score outputs were interpreted correctly by users
Opportunities
- Formalize existing AI drafting behavior with design guardrails
- Encode Weave standards into reusable prompts and patterns
- Ship lightweight tooling with high adoption and low overhead
Process
The work progressed through three phases: baseline and prompt architecture, guided-vs-free-text testing, and Custom GPT delivery evaluation. Each phase was designed to reduce guesswork and make decisions with evidence.
Phase 1
Established a baseline with expert heuristic review, then built an AUTOMAT-based prompt architecture. Also redesigned metric labels to clarify grade-level and reading-ease targets.
Phase 2
Compared guided input against free text while holding the backend pipeline and prompts constant. Guided input improved readability grade overall (-2.86 vs -1.88), with the strongest uplift on warning content.
Phase 3
Evaluated AWS toolkit, Custom GPT, and Cursor workflows. Selected Custom GPT for low-friction drafting, with Cursor as the repo pathway and the app retained as a governance option.
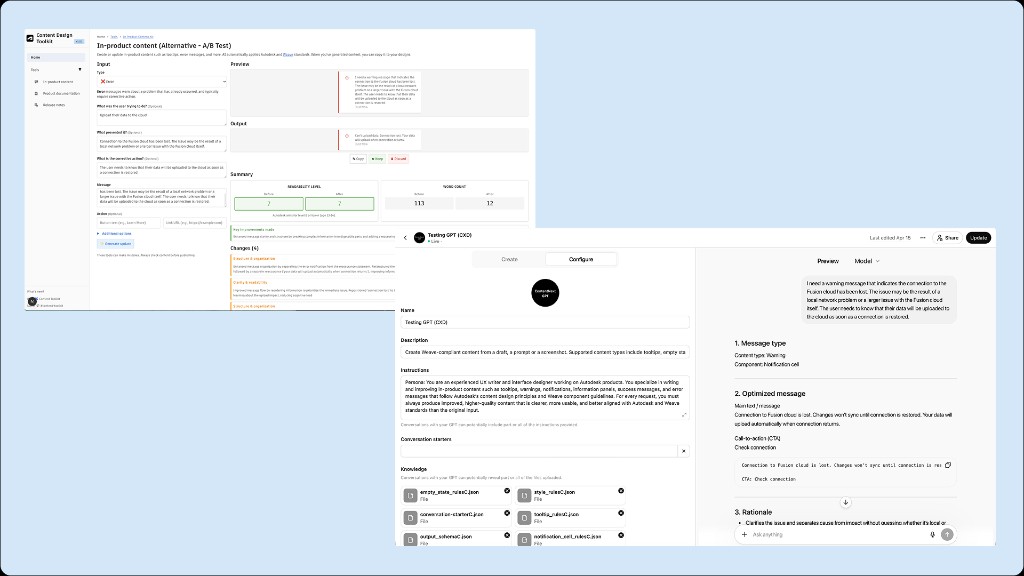
Solution
ContentNext shipped as a system, not just a single tool: a production Custom GPT for zero-friction drafting, Cursor workflows for repo-level pathways, and modular knowledge files for fast iteration. This preserved quality and speed while removing infra overhead from the default path.
What shipped
- Custom GPT in ChatGPT Enterprise for structured in-product content drafting
- Cursor-adjacent workflows for codebase-connected production routes
- Modular prompt stack: GPT instructions, conversation starter, examples, and system prompt
What was paused
- AWS toolkit app paused to avoid infrastructure and maintenance overhead
- Governed app remains a future option when deterministic enforcement is required
Core design decisions
- Meet users where they already work
- Use structure and constraints to make AI reliable
- Treat guided input as behavior design, not just form design
- Stay explicit about evidence limits when quality fields are incomplete
Results
The production decision delivered faster adoption, lower operational burden, and rapid prompt iteration while preserving quality guardrails for in-product content. Readability improvements were measurable, and we documented where further instrumentation was needed.
In the February workbook, guided input won on readability in most paired rows and performed especially well for warning content. The warning group showed an average -4.67 point reduction on the Flesch-Kincaid readability grade, indicating output that is easier to read for a wider range of users. We target a readability grade of around 7 to 8 where possible, while preserving necessary detail and accuracy. Error content was the exception in this sample, which led to a concrete next step: improve the quality of guided error-field completion. We also flagged that B-side quality/compliance/context fields must be fully captured to make stronger A/B claims beyond readability.
Conclusion
ContentNext demonstrated that AI reliability comes from design structure, not model novelty. Prompt engineering, interaction design, and measured experimentation enabled a practical system that scales quality without scaling friction. The strongest strategic lesson was to layer tools by maturity: GPT for adoption, Cursor for integration, and app governance only where strict controls are needed.
Bespoke tools face lifecycle risk
In enterprise settings, custom internal apps can be outpaced by licensed platform tools. Shipping where users already work often improves adoption, cost, and resilience.
Prompt engineering is product design
Quality output required rules, examples, constraints, and maintainable knowledge structures. Designing those systems had direct product impact.
Proxy testing can unlock momentum
When formal research capacity is constrained, structured proxy testing can still produce actionable findings, as long as limits are explicit and follow-up instrumentation is planned.